At scale, every platform or DevOps team runs into the same challenge: Kubernetes infrastructure drifts faster than humans can correct it. Pods are overprovisioned, nodes run unoptimized, horizontal and vertical autoscalers fight each other, and latency spikes during load, even in the most disciplined environments.
It doesn’t matter whether you’re all-in on a single provider or spread across AWS, GCP, and Azure. The core challenge is the same:
How do you keep workloads reliable, efficient, and cost-effective without engineers hand-tuning the system every week?
This is where autonomous resource management comes in. In this post, we’ll break down how resource automation actually works in production, why single-cloud and multi-cloud environments introduce different kinds of operational friction, and how ScaleOps provides a single optimization layer that keeps everything predictable, performance, and cost-effective across any cloud footprint.
How Resource Automation Works in Real Life
Resource automation functions as the intersection of workloads and infrastructure, allowing you to establish application capacity requirements, deployment locations, and resource security boundaries. It then maintains these through continuous comparison between actual conditions and your defined intentions.
An autonomous resource management system manages:
- Pod and replica rightsizing
- Placement and binpacking
- Node consolidation
- Governance
- Context-based scaling
Implementing an autonomous resource management system begins with adopting a control‑plane‑first approach, combining declarative APIs with GitOps workflows and standardized policy sets. This helps organizations minimize one-off, hand-configured clusters while preventing provider-specific drift.
The control plane has a few functions:
- Handles workload scaling and resource optimization
- Maintains default security standards through PodDisruptionBudgets (PDBs), Pod Security Admission (PSA), and OPA/Kyverno and image allowlists
- Enforces SBOM coverage and least-privileged identities for all workloads
The automation layer incorporates governance and safety into the core of the system, treating the two concepts as requirements rather than optional add-ons.
Achieving this autonomous control plane is the key to mastering either single-cloud or multi-cloud. ScaleOps provides a continuous automation and optimization platform, delivering these unique capabilities, whether you choose a single-cloud or multi-cloud strategy.
When Single‑Cloud Wins
Many high-performing teams choose to operate primarily in one cloud because it reduces cognitive load: one IAM model, one billing system, one set of managed services, one operational playbook.
But even in single-cloud setups, Kubernetes scaling complexity remains.
Use Case: A Mature EKS Platform Team
Imagine an AWS platform team running a mature EKS environment: Traffic is spiky, some services tolerate interruptions, while others require strict placement rules.
GPU workloads appear periodically, so they rely on Karpenter NodePools with consolidation and spot orchestration for flexible services. HPA covers fast scaling, VPA and in‑place pod resize address drift, and PDBs protect critical workloads during rescheduling.
In new clusters, the team may also temporarily enable EKS Auto Mode to secure quick capacity before switching back to manual control.
For AWS teams, this stack becomes a concrete EKS cost optimization engine, cutting waste while preserving application reliability. However, there is a trade‑off between convenience and control.
How ScaleOps Helps
ScaleOps resolves the issue of balancing convenience and control by layering intelligent optimization on top of existing autoscalers, delivering:
- SLO‑aware consolidation (no surprises for critical services)
- Intelligent placement that avoids noisy neighbors
- Guardrails that preserve application safety while eliminating wasted resources
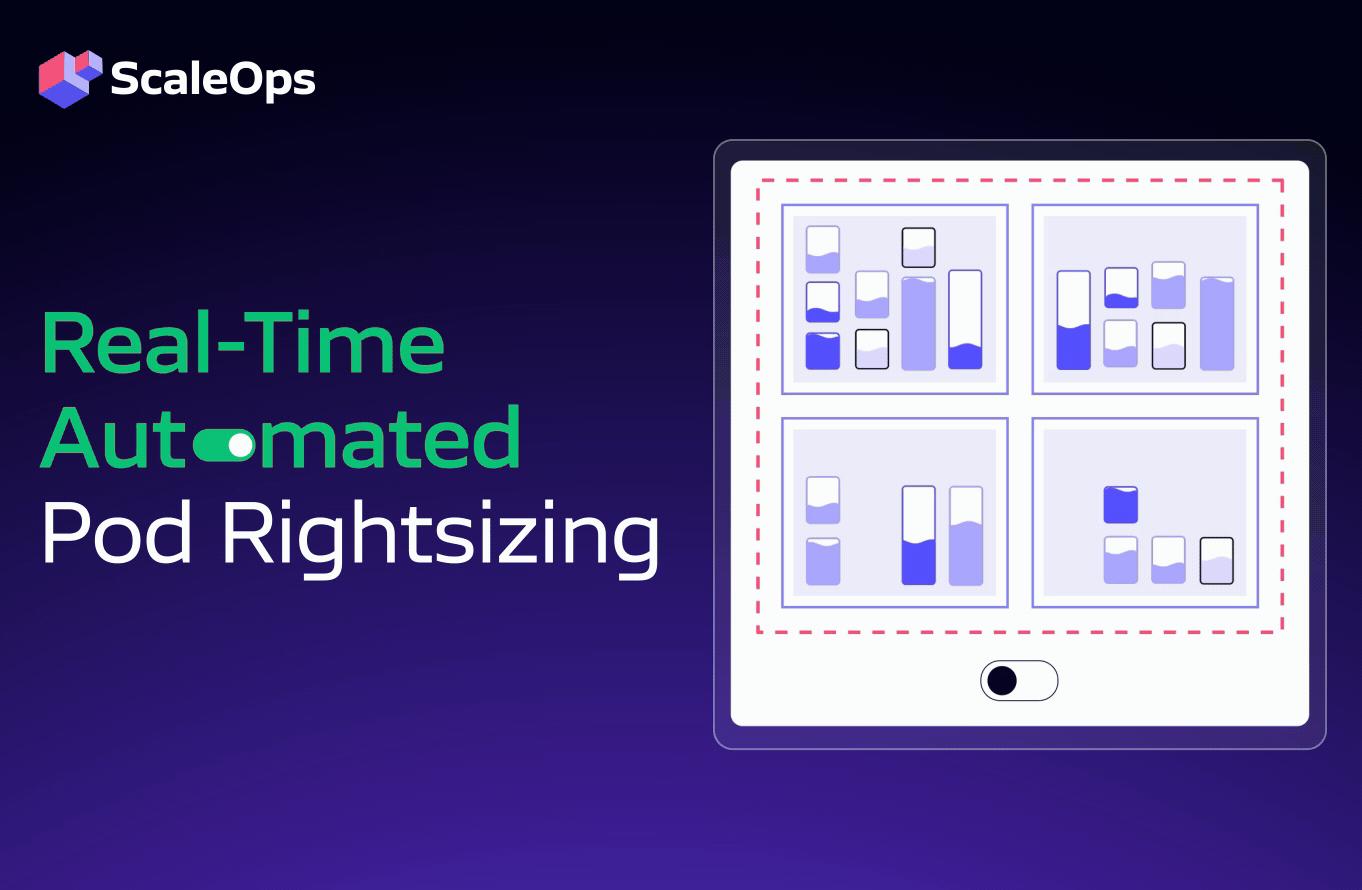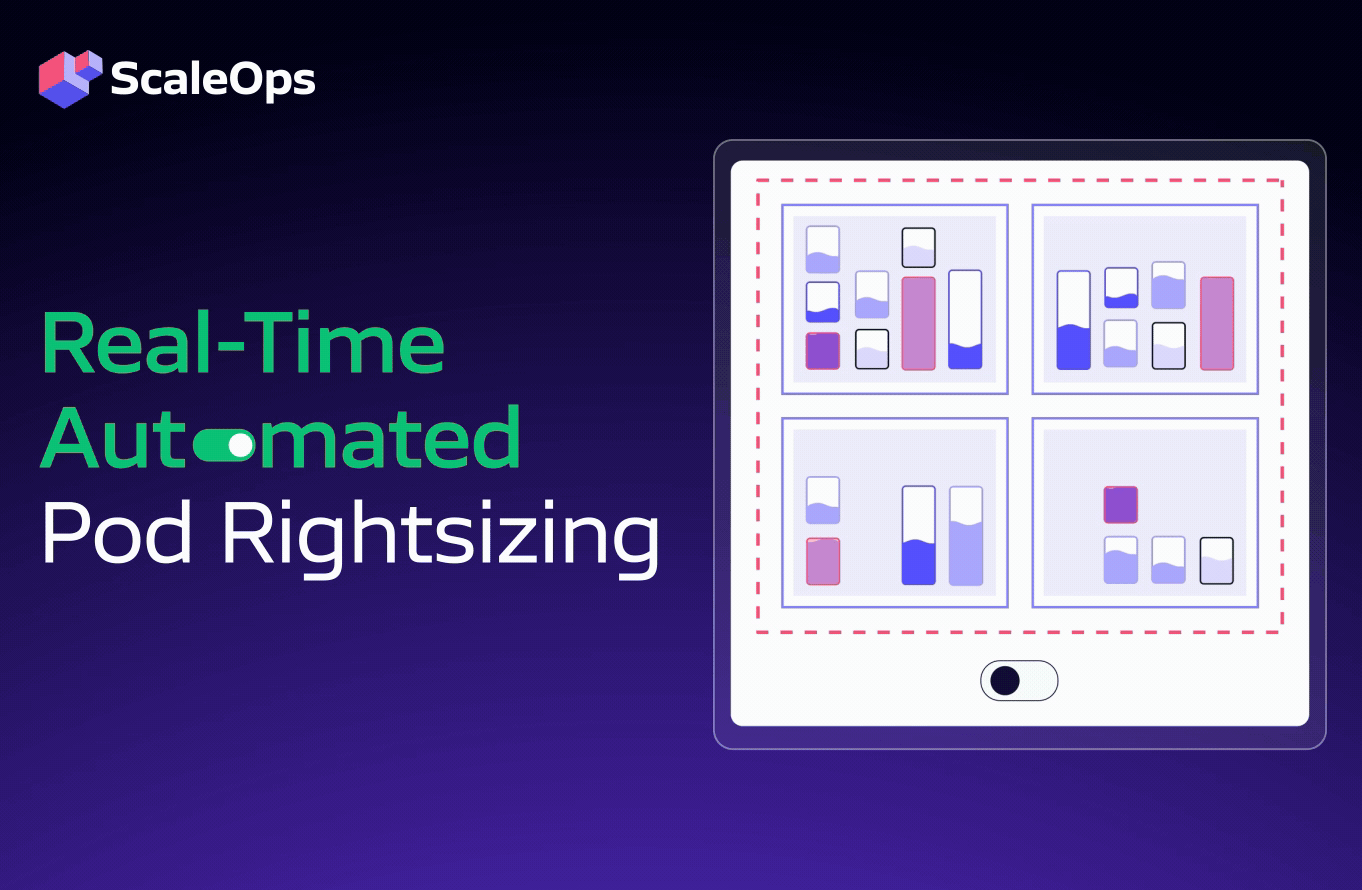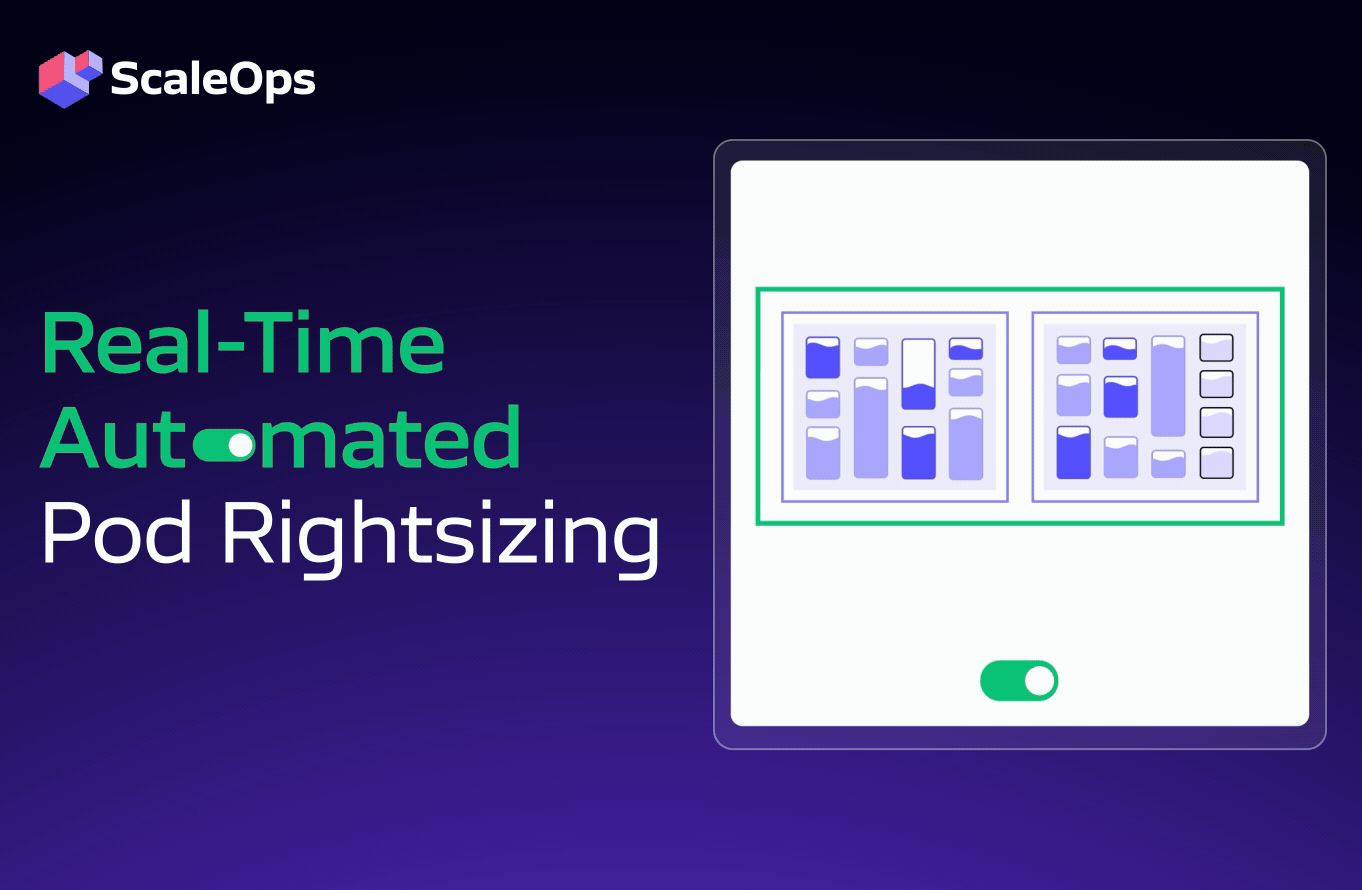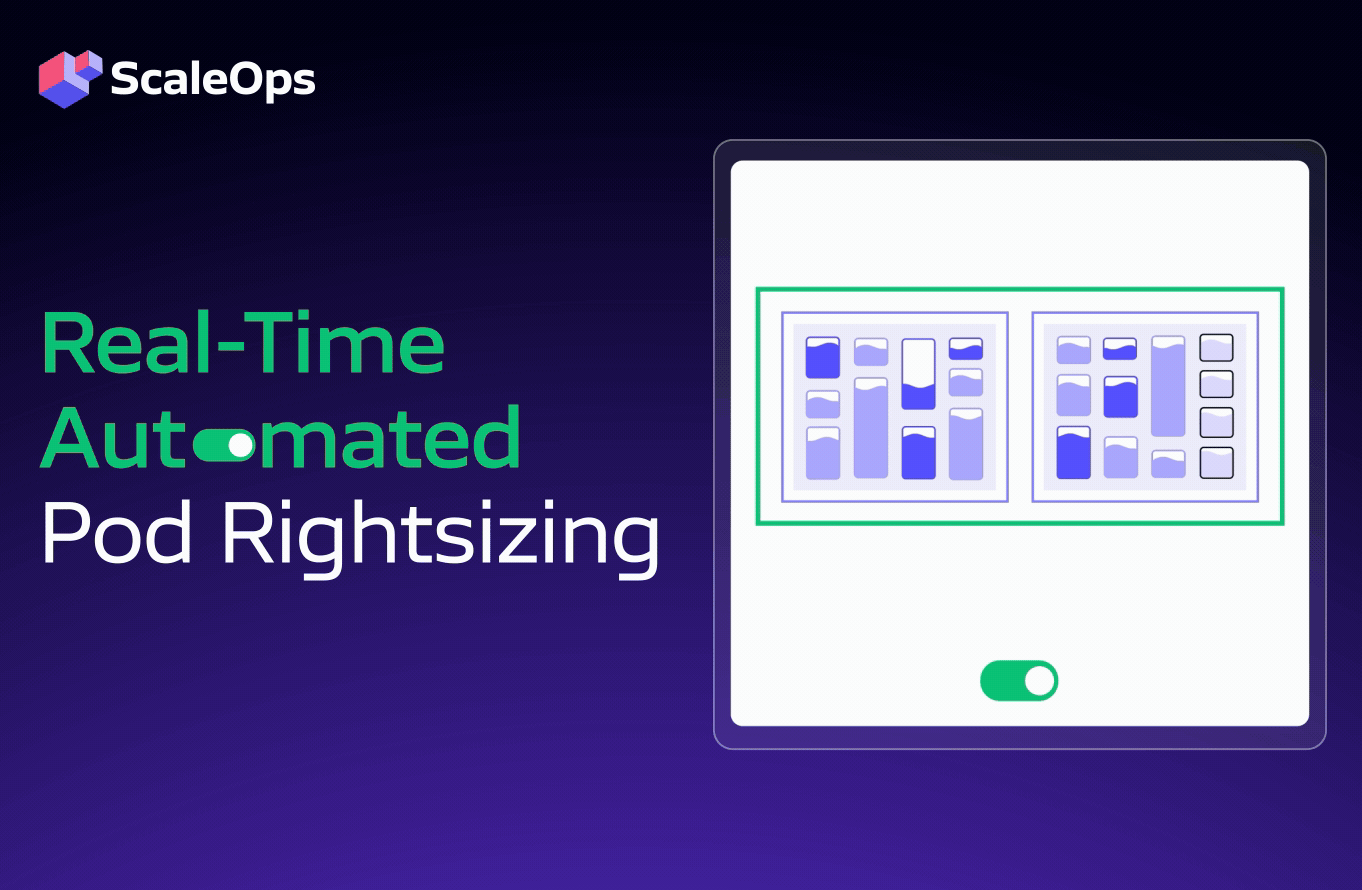
- Automated, real-time rightsizing and in-place optimization
All of this happens without forcing the team to abandon their current autoscaling setup.
You keep the stack you already trust. ScaleOps removes the operational burden.
Why Multi‑Cloud Happens (and How to Make It Simple and Predictable)
Multi-cloud rarely starts as a clean strategy. It happens organically, driven by business needs and pressures:
- One team builds in GCP
- Another inherits an Azure environment
- An acquisition arrives on AWS
- Data residency rules force deployments into new regions
- Or teams want best-in-class managed services from different cloud providers
Over time, companies need to adopt a pragmatic multi-cloud strategy that accounts for expansions in teams and technology, data protection requirements, performance optimization, and security risk reduction.
Without an automation strategy in place, a multi-cloud deployment can lead to:
- Policy drift
- Unpredictable cluster behavior
- Duplicate tooling and services
- Complex billing systems (and many questions from finance)
- Overprovisioning becomes the “safe” default
Use Case: AWS + GCP Team
Imagine a team running critical workloads in both AWS and GCP. They rely on Crossplane or Cluster API to provision clusters on each provider, while GitOps keeps configuration and state consistent. Policy bundles enforce the same guardrails everywhere, and a service mesh provides cross-cluster connectivity and failover when a region or provider has issues.
Simplifying all of this requires you to avoid three common mistakes:
- Designing systems at the lowest common level
- Allowing policy changes between clusters, namely, policy drift
- Creating financial reporting chaos through cost and tagging systems
How ScaleOps Helps
ScaleOps sits on top of the above multi-cloud setup as a cloud-agnostic, consistent optimization and safety layer, across managed, self-hosted, and hybrid clusters. This ensures the same SLO-aware logic is applied everywhere for consolidation, placement, rightsizing, and replica management.
With ScaleOps, multi-cloud becomes predictable rather than a source of operational chaos.
A Cloud‑Agnostic Automation Blueprint
Here is a practical blueprint that works across AWS, GCP, Azure, and hybrid environments.
| Area | Practices |
| Provisioning | – Handle capacity classes through 3 distinct modes: on-demand, spot, GPU – Identify which apps can handle disruptions while enabling users to specify time periods for secure deployment and system migration – Declarative bootstrapping via Crossplane/Cluster API |
| Placement & Bin Packing | – Use topology spread constraints for availability – Taints/tolerations to separate noisy neighbors and QoS/priority classes – Safe-to-evict logic to maintain critical pods in place – Maximize utilization while minimizing impact of failures |
| Rightsizing | – HPA for rapid traffic shits – VPA and in-place resize for drift correction (while accounting for in-place resize’s early maturity and inconsistent support) – Apply SLO-based gating with anti-thrash controls to protect latency – Design the system as an autonomous engine validated in incident reviews |
| Governance & Safety | – Apply PDBs and PSAs consistently so workloads remain protected during disruptions – Use OPA/Kyverno to enforce organizational guardrails and avoid drift or unsafe configs – Enforce image allowlists to ensure only verified artifacts run in production |
This blueprint becomes exponentially more effective when enforced by automation rather than human effort.
Metrics That Prove Your Automation Works
Reliable automation must prove its value with objective data. The following indicators show whether your cloud resource management system is truly efficient, stable, cost‑effective, and secure across any cloud.
Efficiency & Reliability
Track node utilization using the P50 and P95 percentiles, where P50 indicates the typical load and P95 reveals the peak pressure points. Also, monitor wasted CPU and memory resources and a bin packing score that adjusts to different instance types.
P99 latency and service failures experienced by users while the system is autoscaling are also key, along with eviction‑related incident rates.
A properly functioning automation layer will reduce waste via consolidation while maintaining stable tail latency—the experience of your slowest requests, typically measured as P95 or P99 latency.
Cost
Request costs, GPU-hour pricing, idle trends, and spot interruption absorption all indicate how effectively automation converts raw capacity into real business value. These metrics also show how resilient your workloads are to price and availability shifts.
Security & Compliance
Monitor policy drift rate, unsigned image usage, and SBOM coverage to see how quickly your security posture changes over time. These metrics are critical for exposing where unapproved or opaque software may be introducing hidden risks.
Juggling all these metrics—efficiency, reliability, cost, and compliance—is the central challenge. Manually trying to optimize one (e.g., cost) without breaking another (e.g., reliability) is not scalable.
This is why a holistic, automated platform is a core requirement for operating at scale – especially in your most critical production environments.
ScaleOps: Cloud‑Agnostic and Production‑Grade Autonomous Resource Management
ScaleOps provides context-aware, automated Kubernetes resource management. It performs real-time optimization of pods, replicas, nodes, and placement using a single, cloud-agnostic policy set that applies consistently across all clusters. This allows you to avoid creating new runbooks for each cloud platform.
The platform operates as a self-hosted solution, featuring air-gapped capabilities and supporting deployment on any Kubernetes environment, across AWS, GCP, Azure, hybrid, and edge clusters. For teams that prefer a fully managed option, ScaleOps Cloud delivers the exact same optimization, guardrails, and security posture as the self-hosted version, as a hosted service.
On Google Cloud, ScaleOps delivers GKE cost optimization and GKE workload optimization, automatically tuning pod requests, replicas, and placement so that GKE clusters are optimized for cost, without sacrificing performance or reliability.
In Azure environments, ScaleOps applies the same cloud-agnostic policies and automation logic to drive AKS cost optimization, aligning cluster spend with real-time application demand and live cluster conditions, simplifying governance across teams.
ScaleOps also works across all providers with your existing stack—including HPA, VPA, KEDA, Karpenter, and Cluster Autoscaler—so you never have to replace your current scaling stack to adopt the platform.
Key Features
The following capabilities are part of the ScaleOps platform for autonomous resource management for both single-cloud and multi-cloud environments:
- Real-time automated pod rightsizing: Continuous CPU/memory optimization and in-place adjustments are based on SLOs. The ScaleOps platform works out of the box and seamlessly with your existing HPA or Kubernetes Event-driven Autoscaling (KEDA) definitions, with no additional configuration required.
- Automated Java resource management: Automatic tuning of JVM memory and CPU for Java workloads is based on live application behavior, so Java services stay within SLOs without manual heap sizing.
- Node optimization: Safe resource consolidation eliminates waste without compromising SLOs, delivering value for both single-cloud and multi-cloud environments.
- Karpenter optimization: Seamless functioning with existing Cluster Autoscaler or Karpenter setup; additional consolidation protection and advanced scheduling capabilities (SLO compliance) for immediate performance benefits
- Replica optimization: Predictive policy-based scaling operations that work with your existing HPA or KEDA definitions, no new configuration required. This avoids excessive resource allocation and keeps apps responsive even during sudden traffic spikes or load hits
- Safe spot adoption: Workload migration to spot instances across providers without service interruptions, ensuring that cost-efficient capacity shifts never compromise application reliability or user experience
Provable ROI
ScaleOps lets you easily demonstrate value to stakeholders. In fact, ScaleOps customers report instant ROI in some cases. Choose two time periods to assess the effects of automation on clusters—regardless of cloud provider—to highlight financial benefits and improvements in system dependability.
The comparison between clusters should become a standard artifact that appears in every quarterly planning process.
Conclusion: Move Beyond the Single-Cloud vs. Multi-Cloud Debate
A robust automation system enables you to move past the single-cloud vs. multi-cloud debate and make informed choices based on clear outcomes: reliability, cost, and delivery speed.
Companies today need to run efficiently on a single provider and still have the option to extend across clouds with portable policies, consistent optimization, and a shared control plane.
With ScaleOps, autonomous resource management becomes the default, whether you run entirely on AWS or distribute workloads across multiple providers.
By combining multi-cloud resource management with Kubernetes resource automation, ScaleOps provides a consistent way to automate the management of both single-cloud and multi-cloud environments, while delivering measurable cost optimization across EKS, GKE, AKS, or any environments running Kubernetes.
Want to see the ScaleOps platform in action?
- Book a demo with a ScaleOps expert
- Start your 14-day free trial