We’re thrilled to announce that our innovative Pod Placement feature has reached General Availability (GA)! After providing value to many of our customers during the beta program while gathering feedback and performing rigorous real-world validation, ScaleOps is proud to offer this game-changing solution as a production-ready feature for all our customers.
In our previous post, ScaleOps Pod Placement: Optimizing Unevictable Workloads, we introduced the challenges of managing critical, unevictable workloads in dynamic Kubernetes environments. Today, we’re excited to dive deeper into the problem and share how our GA release of Pod Placement effectively solves it, providing up to 50% additional cost savings on top of our standard workload rightsizing.
The Challenge: Beyond Workload Rightsizing
Workload rightsizing is the basic step any team wishing to maximize the ROI of their cloud infrastructure must take. Rightsizing allows the Kubernetes scheduler, together with any Cluster Auto Scaler, to maximize cluster resource utilization by effectively bin packing pods and freeing underutilized compute nodes. This step is essential to enable cost savings without sacrificing suffering from performance or availability issues.
However, modern Kubernetes production clusters often run a mix of workloads—from flexible workloads with evictable pods to a wide range of workloads with pods that can not be touched. Add to the mix that developers who own the workloads add their own scheduling and eviction constraints, such as PDBs and affinity and anti-affinity rules that have a cluster-wide impact, and you get some serious challenges. The result? Even after rightsizing your workloads, a significant amount of resources get strung up as they can not be reclaimed, causing a long lasting impact and degradation of cluster utilization.
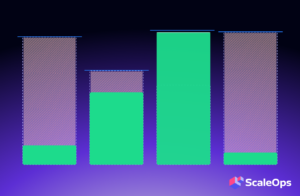
- Pinned Workloads Restrict Bin Packing: Unevictable workloads are “pinned” to specific nodes once scheduled. This immutability prevents the cluster autoscaler from efficiently bin-packing the cluster. The outcome? Underutilized nodes and wasted resources, as these pinned pods restrict the autoscaler’s ability to consolidate nodes and optimize resource utilization. To complicate matters further, these unevictable pods typically have a long lifespan, reducing the effectiveness of bin packing efficiency over time until the pod ultimately terminates and the node can be reclaimed.
- Poor node utilization: With growing cluster sizes and increasingly complex dependencies, ensuring that every unevictable pod lands on the most suitable node is critical to prevent cluster fragmentation and unnecessary compute costs. Without addressing this concern clusters can quickly become underutilized with a large amount of underutilized nodes that translate into a lot of wasted resources being allocated.
- Constrained Scheduling: Affinity and Anti Affinity rules make matters even worse as they further constrain the scheduler forcing a
sub-optimal scheduling plan resulting in a highly fragmented cluster with poor resource utilization.
- Operational Overhead: Traditional scheduling mechanisms can struggle to account for the nuanced needs of critical workloads. This often results in inefficient resource utilization, increased operational complexity, and a higher risk of service disruption.
- Cross-Organization Friction: As developers introduce scheduling and eviction constraints to their workloads, DevOps and Platform teams face an increasing challenge in optimizing cluster utilization. This is especially true in large-scale cloud deployments where the DevOps or Platform team may lack familiarity with the specifics of each workload or direct contact with its developers.
- These challenges often lead to higher cloud bills and excessive operational overhead for DevOps teams.
Our Solution: Intelligent Pod Placement
After examining more than a thousand production clusters running various types of workloads, we acknowledge these challenges and set out to build ScaleOps Intelligent Pod Placement. This new capability provides ongoing optimization. It optimizes the placement of any new pod upon creation and includes advanced scheduling algorithms that optimize the placement of unevictable pods while respecting any taints and affinity rules. The best part? Onboarding is zero-touch, and it doesn’t require any changes to the workload’s manifests or require anything from the workload owners or DevOps teams to start gaining value.
The GA release of ScaleOps Pod Placement addresses these challenges head-on. Here’s how we’re solving the problem:
ScaleOps Pod Placement automatically optimizes pod scheduling decisions to improve bin packing and enhance resource utilization while maintaining stability and availability requirements for workloads. During the extensive beta phase, we observed up to 50% more cost savings on top of the savings of our advanced workload rightsizing.
Here’s how we do it:
✅ Placement of Unevictable Pods: optimizes the scheduling of unevicatble pods, including pods with safe-to-evict=false annotations, PDB restrictions, pods with local storage, Ownerless and Kube System pods. This new capability groups unevictable pods and schedules them together on a set of common nodes to maximize Bin Packing efficiency, increase cluster utilization, and reduce the overall allocated resources.
✅ Node Level Optimization: Deep insight and visibility on different constraints preventing cluster resources from being fully and efficiently utilized and automatically optimizes Cluster Auto Scaler & Karpenter configurations.
✅ Seamless experience: ScaleOps Smart Pod Placement works alongside the default Kubernetes Scheduler and with any Cluster Auto Scaler with no specific onboarding tasks or ramp-up time until gaining full value.
Ready for Production
With Pod Placement now GA, you can confidently use ScaleOps Pod Placement in production environments. Our commitment to continuous improvement means you’ll benefit from ongoing enhancements and expert support, ensuring that your critical workloads are always in the best possible hands.
We invite you to explore the full capabilities of the GA release and get started optimizing your cluster’s workload distribution today.