






Kubernetes Resource Management
on Auto-Pilot
ScaleOps is the only platform that fully automates resource optimization based on real-time demand and application context.
The Complete Platform for Kubernetes Resources
Real-Time Pod Rightsizing
Real-Time Pod Rightsizing
ScaleOps automates resource requests and limits per pod based on real-time demand, freeing engineers from repeated manual tuning of CPU and memory allocation across the cluster. This results in up to 80% cloud cost savings.
Start saving in minutes, not days
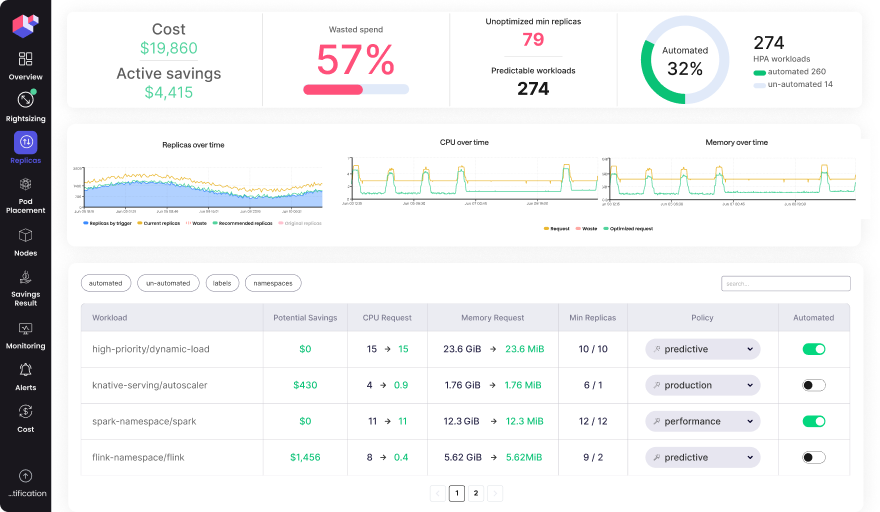
Replicas Optimization
Replicas Optimization
Automatically scale horizontally, before demand hits
Automated Smart Pod Placement
Automated Smart Pod Placement
ScaleOps automates and optimizes the placement of unevictable pods by ensuring pods are correctly allocated on the best nodes to allow underutilized nodes to scale down, resulting in dramatic cloud cost savings by up to 50% without sacrificing performance.
Instant Value with Seamless Automation
Install with a single helm command. That’s it.
Cluster level & Workload level Troubleshooting
Cluster level & Workload level Troubleshooting
ScaleOps provides dashboards and tools for diagnosing issues from cluster-level to specific workloads, enhancing visibility and enabling proactive management.
Your workloads, for 80% less
Cost Monitoring
Cost Monitoring
ScaleOps offers a comprehensive view of compute, network, and GPU costs, enabling better cloud spend management and significant saving
Here’s What People Are Saying About Us
Here’s what people are saying about us
ScaleOps automatically optimizes Wiz’s containers in production according to our real-time needs, improving performance even during demand spikes. While dramatically reducing our K8s costs, the hands-free automation freed our teams from dealing with ongoing configurations, which is critical in our rapidly ever-growing environment
Ron Tzrouya
Director of Cloud Financial Strategy

ScaleOps’ automation optimizes our online applications in production to efficiently meet real-time demand. The significant reduction in cloud costs and elimination of repeated manual work have freed our teams, enabling them to focus on core projects. The fast time to value, particularly after the quick installation, has been immediately beneficial. Additionally, the availability of a 24/7 responsive team of experts is extremely valuable.
Eloise Ann Friedman
Director of Cloud Platform

Manually tuning CPU and memory requests or limits across workloads was eating up our engineers’ time. With ScaleOps automating resource optimization at the pod level, we’ve eliminated constant config changes and cut cloud costs significantly.
Elad Kollender
DevOps Group Manager

ScaleOps automatically manages our resources and continuously optimizes our production workloads in response to demand. This platform has resulted in significant savings, all through a hands-free experience.
Igal Shprincis
Senior Software Engineer

ScaleOps’ automation continuously optimizes our containers on production to meet real-time demand. The 2-minute installation was straightforward, and the immediate value was clear. It’s significantly reduced operational overhead, freeing our teams to focus on more strategic initiatives, while reducing our cloud cost by over 50%
Cristian Felix, Ph.D.
Product and Technology

ScaleOps automatically optimizes Wiz’s containers in production according to our real-time needs, improving performance even during demand spikes. While dramatically reducing our K8s costs, the hands-free automation freed our teams from dealing with ongoing configurations, which is critical in our rapidly ever-growing environment
Ron Tzrouya
Director of Cloud Financial Strategy
ScaleOps’ automation optimizes our online applications in production to efficiently meet real-time demand. The significant reduction in cloud costs and elimination of repeated manual work have freed our teams, enabling them to focus on core projects. The fast time to value, particularly after the quick installation, has been immediately beneficial. Additionally, the availability of a 24/7 responsive team of experts is extremely valuable.
Eloise Ann Friedman
Director of Cloud Platform
Manually tuning CPU and memory requests or limits across workloads was eating up our engineers’ time. With ScaleOps automating resource optimization at the pod level, we’ve eliminated constant config changes and cut cloud costs significantly.
Elad Kollender
DevOps Group Manager
ScaleOps automatically manages our resources and continuously optimizes our production workloads in response to demand. This platform has resulted in significant savings, all through a hands-free experience.
Igal Shprincis
Senior Software Engineer
ScaleOps’ automation continuously optimizes our containers on production to meet real-time demand. The 2-minute installation was straightforward, and the immediate value was clear. It’s significantly reduced operational overhead, freeing our teams to focus on more strategic initiatives, while reducing our cloud cost by over 50%
Cristian Felix, Ph.D.
Product and Technology





