
Today, we are excited to announce a significant achievement for ScaleOps – we have successfully raised $21.5 million in total funding. We’re thrilled to be working with LightSpeed Venture Capital, who led this round, and participating investors NFX and Glilot.
This is an amazing milestone for ScaleOps, and I couldn’t be more proud of what we’ve achieved in such a short time. So, how did we get to where we are today, and where are we headed?
We’re on to something big: Run-time Automation of Cloud-Native Resource Management
As cloud-native environments become increasingly dynamic and subject to constant change in demand, managing cloud resources has become extremely complex, challenging, and tedious to maintain.
The configurations for container sizing, scaling thresholds, and node type selection are static, while consumption and demand are dynamic. This means engineers are required to manually adjust cloud resources to meet fluctuating demand and avoid under or overprovisioning, resulting in millions of dollars being wasted on idle resources or poor application performance issues during peak demand.
For production environments, every container requires a different scaling strategy. Experienced engineers spend hours trying to predict demand, running load tests, and tweaking configuration files for each container. Managing this at scale is nearly impossible.
Even if the engineers decide to take action, all the existing solutions have the same problem. The resource allocation is static, while the resource consumption is dynamic and constantly changing.
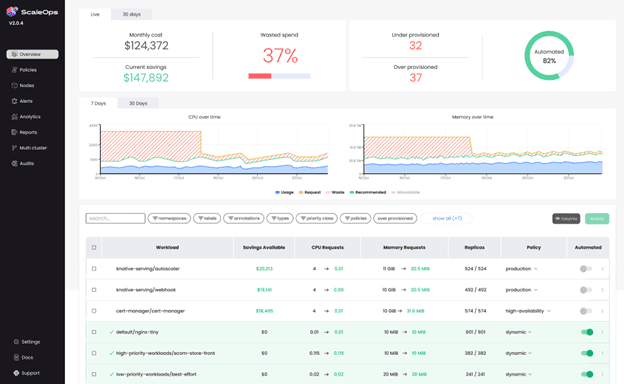
We realized the only way to free engineers from ongoing, repetitive configurations and allow them to focus on what truly matters is by completely automating resource management down to the smallest building block: the single container in run time.
We built an application context-aware platform that automatically optimizes these constantly changing environments, adapting to changes in demand, in real-time. ScaleOps leverages algorithms to analyze, predict, and automatically allocate resources according to demand, ensuring optimized application performance without any manual intervention.
Our vision is clear – ScaleOps empowers engineers with a platform that automatically streamlines resource management, enhances the overall efficiency of cloud-native applications, and ensures cost-effectiveness.
It’s all about the team
So how did we get to where we are so fast?
What sets ScaleOps apart is not just the great product we built, but also our strong team and great culture. And we couldn’t get to where we are without this team.
We move fast. We make fast decisions and believe in simplicity. Above all, we are obsessed with our customers and delivering fast to their biggest pain points and challenges.
Our team has grown to over 30 people, spread geographically between Tel Aviv and distributed around the US. Our next step is scaling up further: investing in R&D to improve and expand our product offering and growing our go-to-market team to deepen our market presence.
A huge thank you to all our investors, partners and customers – this achievement is as much yours as it is ours.
We can’t wait to see what’s next.



