As the usage of Kubernetes as a cloud-native platform increases, the efficient management of computing resources for pods has become increasingly challenging. The efficient use of resources can significantly impact the performance and costs of a workload.
In order to increase efficiency, many organizations resort to manual tuning, which can be repetitive, time-consuming, and mostly ineffective. Besides manual tuning, other solutions are available such as Vertical Pod Autoscaler (VPA) and Goldilocks.
In this blog, we will explore the options available and look for the most effective solution to tackle this growing challenge.
Monitoring and Manual Tuning
Monitoring the workload resource consumption is crucial in determining the precise resource requests and limits. By monitoring resource usage, you can better understand how many resources each pod needs. This information is critical in determining the right resource requests and limits to set.
There are several ways to monitor pods’ actual resource consumption.
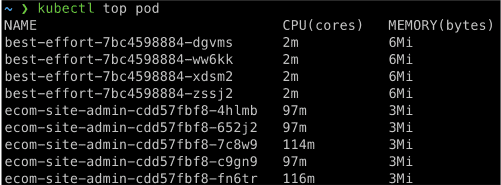
Kubectl top pod
One of the simplest ways is to use the “kubectl top pod” command. However, this method only provides a snapshot of current resource utilization and doesn’t consider resource usage over time.
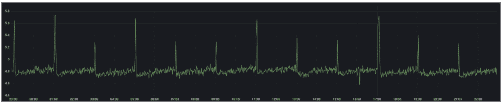
Prometheus and Grafana
A more advanced way of monitoring is using dedicated solutions such as Prometheus and Grafana. These tools provide a comprehensive view of resource usage over time, which can help better understand pods’ resource consumption patterns.
Monitoring the resource consumption of each workload and manually adjusting resource requests and limits can be repetitive and time-consuming, especially when managing multiple workloads.
VPA – Vertical Pod Autoscaling
The Vertical Pod Autoscaler (VPA) is an open-source tool designed to eliminate repetitive workload monitoring and help adjust pods’ resources either by recommendation or automation.
The VPA analyzes pod resource consumption over time and uses this data to make recommendations for the correct resource configuration. It uses historical data to provide recommendations, which are then applied to the pods in the form of resource requests and limits.
VPA has three operation modes –
- “Recreate” (Automation) – VPA adjusts resource requests and limits on pod creation and also updates them on existing pods by evicting them when the requested resources differ significantly from the new recommendation.
- “Initial” – VPA only assigns resource requests and limits to pod creation and never changes them later.
- “Off” (Recommendation) – VPA does not automatically change the resource requirements of the pods. The recommendations are calculated and can be inspected in the VPA object.
Benefits of VPA
Ease of Use
VPA is relatively easy to use and can be set up with a few simple commands, making it more accessible.
Time Management
VPA saves time by automating the process of monitoring resource consumption and determining recommended values for resource requests and limits.
Improve Utilization
Applying the VPA recommendations leads to improved performance and cost reduction on compute because pods only consume the resources they require.
VPA Limitations
Production Limitations
Both “Recreate” and “Initial” modes are not recommended for production, as they can result in frequent pod restarts and application downtime.
Down Time
“Recreate” and “Initial” modes don’t recover fast from a lack of resources, which may cause container downtime or even an infinite loop of failures.
Policy Flexibility
Lacks policy flexibility, as not all workloads are the same and may require different resource headroom, history windows, percentiles, etc.
HPA Limitations
“Recreate” mode won’t work with HPA (Horizontal Pod Autoscaler) using the same CPU and memory metrics because it would cause “competition” between both. Therefore, if you need to use both HPA and VPA together, you must configure HPA to use a custom metric.
Historical Data
VPA requires extensive historical data to make accurate recommendations, which may result in suboptimal resource allocation during the initial period.
GoldiLocks
Goldilocks is an open-source solution that recommends how to set resource requests and limits for your pods. It uses the “Off” mode of the Vertical Pod Autoscaler (VPA) to receive right-sizing recommendations for every workload. Goldilocks provides a visualized dashboard with VPA recommendations, making it easier to view and understand resource recommendations for each deployment.
The dashboard displays recommendations for the Guaranteed and Burstable Quality of Service (QoS) classes.
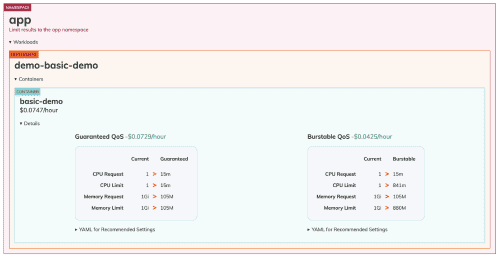
(Source: https://goldilocks.docs.fairwinds.com/)
Automation is the Key
Using solutions that only provide recommendations can be problematic in Kubernetes environments. While recommendations can be useful in helping engineering teams understand which resource requests and limits should be set for their workloads, relying solely on recommendations can waste precious engineering time. Teams are still required to manually implement recommendations and continuously monitor their workloads to ensure they are running optimally, which can be repetitive and time-consuming.
Relying solely on recommendations may lead to subpar performance and costly workloads, as the recommendations may not accurately reflect the ever-changing needs of the environment. In dynamic and constantly evolving environments, a solution that provides only recommendations is not enough to guarantee the best performance and cost efficiency.
ScaleOps is the ultimate solution for optimizing and scaling Kubernetes workloads because it eliminates the need for repetitive and time-consuming manual tuning and monitoring of resources.
With ScaleOps, workloads receive the exact amount of resources they need in terms of performance and cost without disruptions or downtime. The platform continuously and automatically right-sizes pod resources during run-time, freeing up valuable engineering time to spend on more significant tasks. By continuously monitoring and adjusting resources, ScaleOps ensures that every workload gets exactly what it needs. This results in optimized performance and up to 80% cost savings.