
We’ve all been there. You deploy a new microservice, and you hear that little voice reminding you to set CPU and memory requests and limits. And then the sacred ritual begins: the wild guess. 100m? 500Mi? Who knows?
You deploy, cross your fingers, and wait for the first OOMKilled alert or the first cloud bill to remind you just how wrong you were. There has to be a better way.
After years of watching teams struggle with Kubernetes resource optimization (and before that with x86 virtualization), we see the same trends repeating themselves:
- Over-provision “just to be safe” and burn 70% more cloud spend.
- Under-provision and risk major hits to performance and reliability.
But let’s face it, Kubernetes resource optimization in 2025 isn’t just about cutting costs. It’s about building systems that can handle AI workloads, edge deployments, and traffic patterns that would make your 2020 architecture cry.
Let’s explore five practical strategies that actually work, the hidden challenges most teams overlook, and the right solutions that are moving the needle.
What is Kubernetes Resource Optimization?
Kubernetes resource optimization is the continuous process of rightsizing CPU and memory allocation to match actual workload demand while maintaining performance and reliability.
This involves balancing three critical components:
- Resource Requests: Minimum guaranteed resources for scheduling
- Resource Limits: Maximum allowed resources before throttling
- Actual Usage: Real-time consumption driving optimization decisions
Optimization isn’t a “set it and forget it” task. Resource needs constantly change based on traffic patterns, feature releases, and seasonal demand.
Why Kubernetes Resource Optimization Matters
Waiting for performance issues or shocking cloud bills before addressing resource management is expensive and reactive.
The business impact is immediate:
- Revenue Loss: 100ms delay cuts conversions by 7% (Akamai report)
- Budget Drain: Overprovisioning wastes 70% of cloud spend
- Customer Experience: Underprovisioning causes service disruptions
It’s no surprise that in a CNCF survey , the top reasons for rising Kubernetes costs are related to poor resource management practices:
Paying for Idle Resources
Overprovisioning = cloud waste. It accounts for 70% of unnecessary cloud spend. That’s like renting a mansion and only using two rooms. For a mid-sized company spending $200K a month on cloud, that could mean $45K wasted every month. At enterprise scale, it can easily reach six or seven figures. That’s money that could fund new engineers, product investments, or just not be spent at all.
CPU Throttling and OOMKills
Underprovisioning is just as bad. It guarantees poor performance and service disruptions. Nothing ruins a customer’s day faster than a 503 error during checkout because a pod got OOMKilled. It’s a balancing act: while overprovisioning wastes money, resource constraints, like CPU throttling and OOMKilled errors, remain a primary cause of application instability.
Noisy Neighbor Problems
Without proper resource limits, one misbehaving pod can monopolize a node’s resources and crash every other service it hosts. This “noisy neighbor” problem is especially dangerous in Kubernetes. Unlike heavily isolated virtual machines, pods are processes sharing the host’s kernel. A single runaway application, if not properly contained by kernel-level safeguards, can choke an entire node.
5 Comprehensive Kubernetes Resource Optimization Strategies
This is where we go deep. For each strategy, we’ll break down:
- The Standard Advice you’ve probably already heard
- The Hidden Challenge that makes it harder in practice
- The Intelligent Solution that holds up in production
1. The Foundation: Getting Requests and Limits Right (Finally)
The Standard Advice: “Set appropriate CPU and memory requests and limits for every container, and rightsize them based on actual usage.”
The Hidden Challenge: This is where 90% of teams struggle. It’s not just about setting values, it’s about continuously managing them. The traditional approach becomes a painful cycle: guess values, wait for issues, check metrics, update YAMLs, repeat. Tools like VPA can help, but they bring their own baggage: pod restarts during business hours, zero cluster-wide context and awareness, and complete failure with complex patterns like “high CPU mornings, high memory nights.”
The Intelligent Solution: Effective optimization solutions need more than basic averages. You need multi-layered analysis, fast-reaction capabilities to catch immediate issues like memory leaks and traffic spikes, and long-term pattern detection for weekly and seasonal trends.
If your API spikes to 890m CPU every morning at 9 AM, that’s not noise, it’s a pattern to accommodate. When memory drops 60% on weekends, that’s thousands of dollars in potential savings.
Application context-awareness is critical. The platform must know that a database and a batch job have different resource needs and act accordingly. It must also process real-time cluster signals, translating events like failed liveness probes or node pressure into immediate, stabilizing actions. The entire point is to automatically connect infrastructure behavior to business outcomes, preserving your performance targets and SLOs.
2. Intelligent Autoscaling: From Reactive to Predictive
The Standard Advice: “Use Horizontal Pod Autoscaler (HPA) to scale based on metrics.”
The Hidden Challenge: HPA (and even KEDA) is fundamentally reactive. It waits for metrics to cross a threshold before acting. This creates a cascade of problems:
- Cold start delays as pods scale gradually from 2 → 4 → 8 → 10.
- Constant “thrashing” as the system fights to scale up and down.
- And the inherent metric lag. By the time your CPU hits 80%, users are already feeling the slowdown.
The Intelligent Solution: Modern autoscaling platforms are shifting from reactive to predictive models. They analyze and learn from historical patterns to anticipate traffic spikes before they happen.
A smart system knows that Monday mornings aren’t like Friday afternoons. That end-of-month processing creates predictable spikes. And that B2B traffic disappears on weekends. It has the foresight to keep performance consistent and scale out minutes in advance of a predictable event, not in response to it.
This predictive approach eliminates the traditional trade-offs. You no longer have to choose between cost (keeping minimal replicas) and performance (overprovisioning for peaks). The system dynamically manages your baseline based on predicted demand, scaling up 15 minutes before your morning rush and scaling down during quiet periods, all while preventing cold starts and maintaining (and sometimes even maximizing) consistent, reliable performance.
3. Mastering the Cluster Level: Intelligent Node Management
The Standard Advice: “Replace the slow cluster-autoscaler with a modern alternative like Karpenter for faster, more efficient node provisioning”
The Hidden Challenge: While tools like Karpenter dramatically improves provisioning speed and reduces instance sprawl, it remains fundamentally reactive. This creates new operational pain points
- The “Just-in-Time” Delay: Even Karpenter’s sub‑minute node launches can be too slow for critical workloads. Every second a latency‑sensitive pod sits
Pendingis a potential outage or failed SLA. - The Headroom Dilemma: Karpenter excels at “tightly packing” pods onto the cheapest node. This backfires when using VPA, which needs extra headroom to grow a pod’s resource requests. With no spare capacity, VPA’s attempt to resize a pod triggers a disruptive eviction and rescheduling cycle.
- Cost-Driven Packing vs. Performance: Optimized bin packing can place noisy and bursty workloads on the same node as latency-sensitive applications. While technically efficient from a cost perspective, it degrades performance of critical services if no safeguards are in place.
The Intelligent Solution: Advanced platforms go beyond reacting to scheduling events, they proactively manage capacity signals and orchestrate capacity according to deeper workload insights and cluster behavior. They pre‑provision exactly the right infrastructure before pods hit Pending. Key techniques include:.
- Right‑Sizing by Profile: Instead of treating every node the same, the platform selects CPU‑optimized instances for heavy compute jobs and memory‑optimized instances for caches and databases, ensuring you never waste dollars on a “balanced” node that underutilizes one resource while overprovisioning another.
- Calculated Elastic Headroom: By intentionally leaving a small, dynamically tuned percentage of each node’s capacity unclaimed, the system guarantees that VPA‑driven scaling can occur in place without evictions, which would otherwise trigger the creation of a new node and leave a Pod in `Pending` until that node becomes available. This buffer adapts to workload variability, so you maintain both dense packing and smooth vertical scaling.
- Performance‑Aware Placement: The orchestrator tags latency‑critical services and steers bursty or noisy workloads away from their nodes, applying soft affinity or anti‑affinity policies as needed. This ensures your SLAs stay intact even when mixed job types coexist in the same cluster.
Swapping in Karpenter solves speed and sprawl, but it still leaves you exposed to vertical‑scaling hiccups and noisy‑neighbor interference. The real game‑changer is a continuous capacity‑orchestration layer that understands each workload’s profile, keeps elastic headroom for growth, and proactively steers placements. Anticipating capacity requirements prior to their impact on your cluster ensures robust performance isolation while maximizing the cost benefits of high-density packing.
4. Multi-Tenancy Without the Warfare: Dynamic Resource Governance
The Standard Advice: “Use ResourceQuotas per namespace and understand QoS classes.”
The Hidden Challenge: In practice, multi-tenant Kubernetes environments often devolve into resource turf wars. Team A hoards resources “just in case,” setting requests far above actual usage. Team B then can’t deploy critical services because static quotas are exhausted. Meanwhile, Finance demands accurate chargeback but gets incomplete or inaccurate data. And DevOps is stuck in the middle, spending more time mediating disputes than scaling infrastructure.
Traditional ResourceQuotas make this worse. They’re rigid, static limits that encourage hoarding and don’t reflect actual usage or business priorities. This rigidity introduces a silent killer: imagine VPA attempting to optimize a workload. The admission controller tries to update a pod’s resource requests to match actual usage, but the new value exceeds the namespace ResourceQuota. The pod is evicted to apply the new setting, but because of the quota violation, it can’t be rescheduled. What was meant to improve efficiency instead took down a live service.
The Intelligent Solution: A modern platform transforms multi-tenancy from a source of conflict into a source of efficiency by focusing on actual usage, not static allocations:
- Real‑Time Rightsizing under Quota Constraints: It starts by removing the need to hoard resources. Instead of allowing teams to defensively over-provision, it must automatically rightsize workloads in real-time based on actual usage and application context. As a golden rule, it must check the target namespace’s quota before making any changes to ensure a newer, higher resource request will be accepted. This prevents the “silent killer” scenario where an automated update accidentally evicts a pod that can’t be rescheduled due to its increased request value. When teams trust that resources will be available when they need, they suddenly stop overprovisioning (or hoarding).
- Granular, Usage‑Based Chargeback: This real-usage data then feeds directly into a granular cost attribution engine. Finance gets precise, real-time chargeback data down to the container level without relying on inconsistent manual tagging. When the data team runs a large job, they’re able to see its exact cost. This encourages natural, bottom-up self-optimization.
- Dynamic Priority and QoS Management: For truly mission-critical workloads, you can still assign Guaranteed QoS and a high PriorityClass to ensure resource guarantees under node pressure. Alternatively, some workloads benefit from a burstable QoS class with high requests: they gain the ability to seize unused capacity when it’s available, improving utilization. However, that approach carries a caveat: if the node becomes memory‑ or CPU‑constrained due to other high‑priority Guaranteed pods, burstable workloads may be throttled or evicted unexpectedly. The best practice is to weigh the likelihood of contention. If you expect frequent peak load spikes, Guaranteed QoS offers predictability; if your cluster generally runs below capacity, burstable can boost overall efficiency.
Finally, optimization settings must adapt to time of day, seasonality, or business cycles. During peak hours, you can apply conservative scaling and stricter placement; off‑peak, allow more aggressive rightsizing or bursty behavior. This flexibility ensures that resource policies always align with real operational priorities.
5. Cloud Cost Intelligence: Making Every Dollar Count
The Standard Advice: “Use Spot instances for non-critical workloads and implement FinOps practices.”
The Hidden Challenge: Kubernetes operates in a resource abstraction layer. It sees CPU cores and memory, not dollar signs. This disconnect makes real-time cost visibility and control problematic. Teams are flying blind, unaware of how much their pods actually cost until the bill arrives. Cloud provider cost data lags by 24-48 hours, making real-time optimization impossible. As a result, most teams either avoid Spot entirely, leaving massive savings on the table, or use it incorrectly and are blamed for production outages when instances disappear.
The Intelligent Solution: The resource optimization platform must bridge the gap between Kubernetes resources and cloud costs, bringing financial intelligence directly into the orchestration layer. This isn’t just about cloud cost observability, it’s about automating the management of cost-aware decisions in real-time.
Developers and application teams should be able to see what their workloads cost per hour, broken down by CPU, memory, and other factors. When cost becomes visible at the pod-level, optimization suddenly becomes actionable. This intelligence then drives smarter Spot instance management. Moving beyond simple “stateless = Spot” rules, the platform analyzes workload characteristics to determine true Spot safety. From there, it can implement policy-driven strategies, like running 70% of replicas on Spot, with automatic fallback to on-demand, balancing savings with reliability. When a data pipeline that typically runs at $15 per hour suddenly spikes to $800 per hour, it shouldn’t just trigger a generic alert. The platform must immediately surface detailed cost breakdowns that allow teams to immediately pinpoint the source of the spike, like inefficient data transfer in a specific workload, and take action.
Ultimately, the platform must optimize for sustained savings through policy-driven automation. For example, schedule policies should automatically shift workloads between aggressive optimization at night and high-availability during peak hours. When combined with intelligent Spot management and real-time cost tracking, this creates a system that optimizes continuously, adapts to your changing business needs, without sacrificing performance and reliability.
Essential Tools and Automation for Kubernetes Resource Optimization
Production Kubernetes environments rely on standard resource management tools. Understanding their limitations is crucial for effective automation.
| Tool | Function | Limitation |
| VPA | Adjusts pod CPU/memory requests | Disruptive restarts required |
| HPA | Scales replica count | Purely reactive to metrics |
| KEDA | Event-driven scaling | Still reactive, not predictive |
| Karpenter | Node provisioning | Reacts to pending pods |
The production reality: These tools operate in silos, often fighting each other instead of working together.
Best Practices for Production Kubernetes Resource Management
High-performing platform teams follow these proven practices:
- Automate Rightsizing: Continuously manage CPU/memory requests based on actual usage, not manual guesses
- Predictive Scaling: Scale replicas before traffic spikes hit, not after latency degrades
- Continuous Node Optimization: Consolidate workloads and terminate underutilized nodes automatically
- Cost Visibility: Show real-time hourly costs in dashboards to drive engineer accountability
- Intelligent Spot Usage: Use policy-driven workload analysis, not simple stateless/stateful rules
From Manual Toil to Intelligent Automation: The Path Forward
Let’s be clear: this isn’t just about improving Kubernetes. It’s about transforming how teams manage cloud resources. At scale and across any environment. The difference between teams struggling with resource management and those who have mastered it comes down to one thing: automated resource optimization that’s application context-aware, happens in real-time, and production-ready.
Manual analysis, static configurations, and reactive fixes just don’t cut it anymore. Not with AI workloads demanding GPUs one minute and sitting idle the next, global applications serving traffic across multiple time zones, and cloud bills that spiral out of control in hours.
There’s a better way, one that’s built for today’s reality:
- Automated Rightsizing: Real-time, application context-aware decisions based on actual usage patterns, not static guesses.
- Predictive & proactive Autoscaling: Stay ahead of traffic spikes and prevent performance issues before they happen.
- Multi-Tenant Fairness:
ResourceQuota-aware optimization that eliminates team conflicts. - Real-time cost attribution: Container-level cost attribution with real-time cloud pricing data.
The capabilities are real, the platforms exist, and the patterns are proven. The question isn’t if you can stop guessing, but how. It’s time to start running Kubernetes like it’s 2025, and that’s where ScaleOps comes in.
How ScaleOps Makes Modern Kubernetes Resource Optimization Actually Work
Most platforms stop at alerts, dashboards, or basic tuning. ScaleOps goes further, it’s the platform trusted across industries and thousands of production clusters to automatically manage Kubernetes resources in real-time, without disruption and without adding engineering overhead.
Kubernetes is just the beginning. ScaleOps makes resource management fully automated and application context-aware, so developers can keep shipping while the platform handles the complexity behind the scenes. No APIs to learn. No YAML to write. No learning curve.
ScaleOps is fully self-hosted and production-safe, with built-in support for GitOps workflows and air-gapped environments. All optimizations happen in-place, with no cold starts, restarts, or surprises.
Here’s how you can get started:
- Step 1: Deploy & Discover. Install ScaleOps in minutes with a single Helm command, then start monitoring resource wastage, cost‑saving opportunities, and resource‑optimization suggestions on the dashboard.
- Step 2: Rightsize & Optimize. Select a few production workloads, enable ScaleOps Rightsizing automation, and watch policies automatically adjust CPU and memory requests to achieve the ideal balance between performance and cost savings. You can then automate the entire cluster with a single click or via Kubernetes‑native policies (Custom Resources). New deployments will immediately benefit from continuous resource optimization while remaining GitOps‑compliant.
- Step 3: Replicas Optimization. Enable predictive autoscaling to automatically suggest and apply optimal replica counts based on historical usage patterns. Smooth out traffic spikes, avoid over‑provisioning, and keep your services performant under load without manual HPA adjustments.
- Step 4: Karpenter and Spot. Integrate with Karpenter to provision Spot instances for non‑critical workloads, then apply Spot‑optimization policies to shift the right pods onto discounted capacity. Capture an additional layer of cost savings while maintaining high availability and resiliency.
ScaleOps delivers true multi‑dimensional Kubernetes optimization: rightsized workloads, eviction‑free resource tuning, and predictive replica scaling all working in harmony to boost application performance, stability, and cost efficiency. Instead of fractured point solutions, you get a single GitOps‑compliant control plane that continuously manages capacity, adjusts resource requests, and steers traffic patterns across your entire cluster.
Deploy it once and watch as your nodes, pods, and replicas self‑optimize for every workload characteristic. No manual tweaks, no firefighting, just real-time automation that is trusted in thousands of production clusters.
Others are still guessing while ScaleOps users are saving millions.
ScaleOps delivers everything we’ve discussed in this guide:
- Continuous rightsizing that eliminates over-provisioning.
- Predictive autoscaling that prevents performance issues.
- Multi-tenant fairness that ends resource conflicts.
- Intelligent Spot management based on real‑time workload requirements.
- Real-time cost attribution down to the container level.
The proof is in production: teams using ScaleOps see instant ROI on their investment, with no impact on performance.
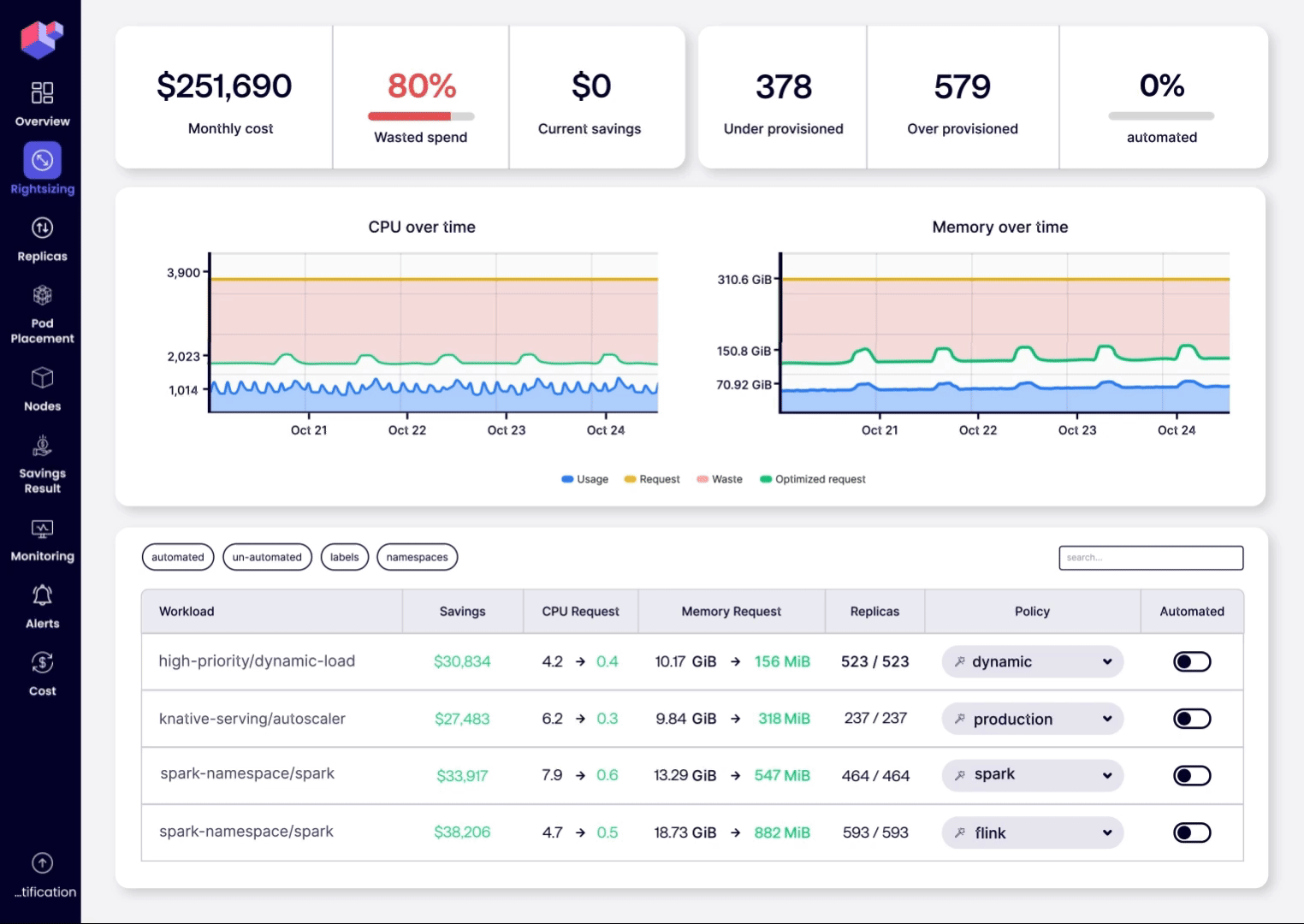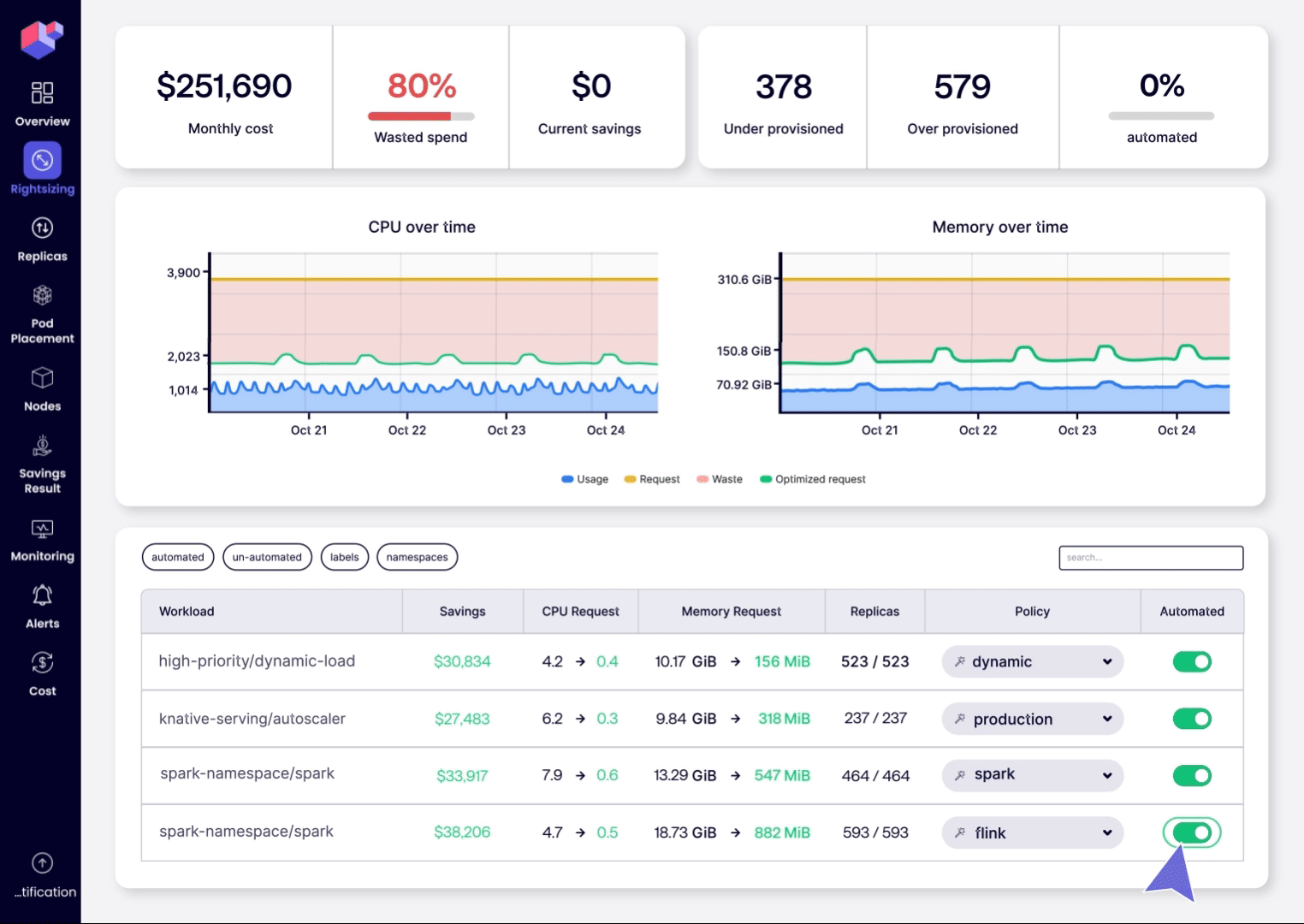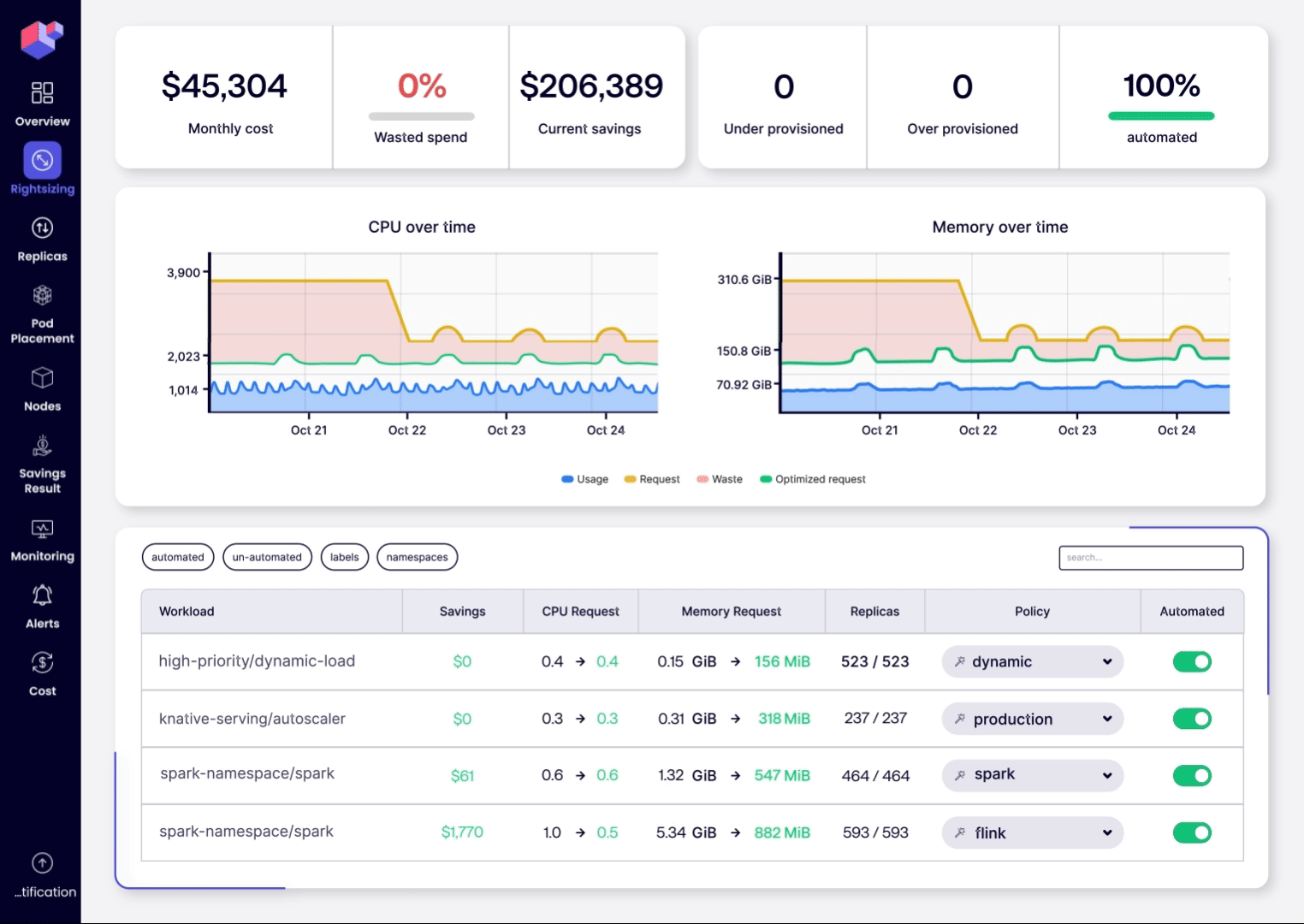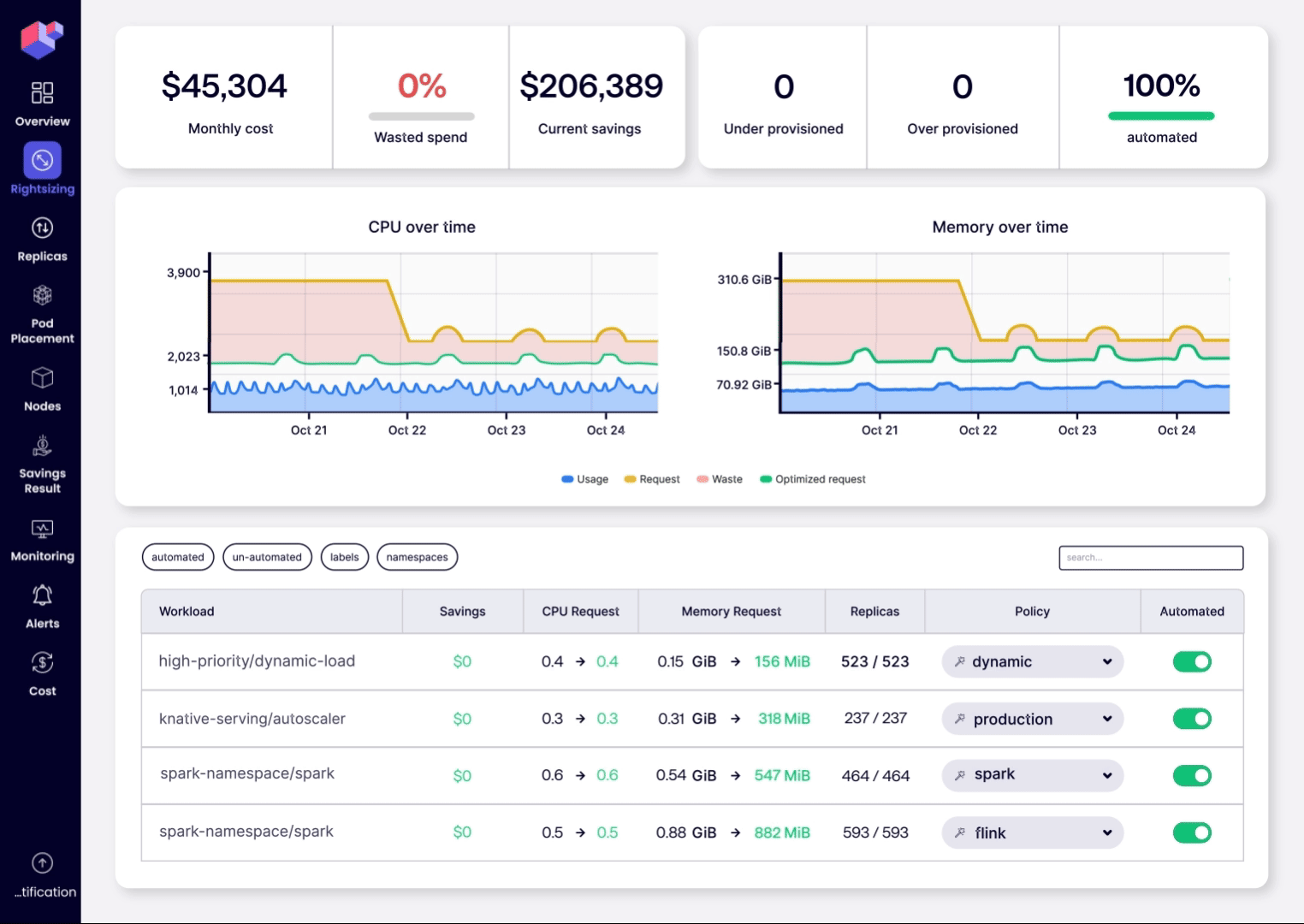
Your next step: starving saving.
- Book a live demo to see your actual workloads optimized in real-time.
- Start your free trial and get real savings in under 24 hours.


