GPU Cost Optimization in Kubernetes: From Waste to Efficient AI Infrastructure
Konstantin Zelmanovich
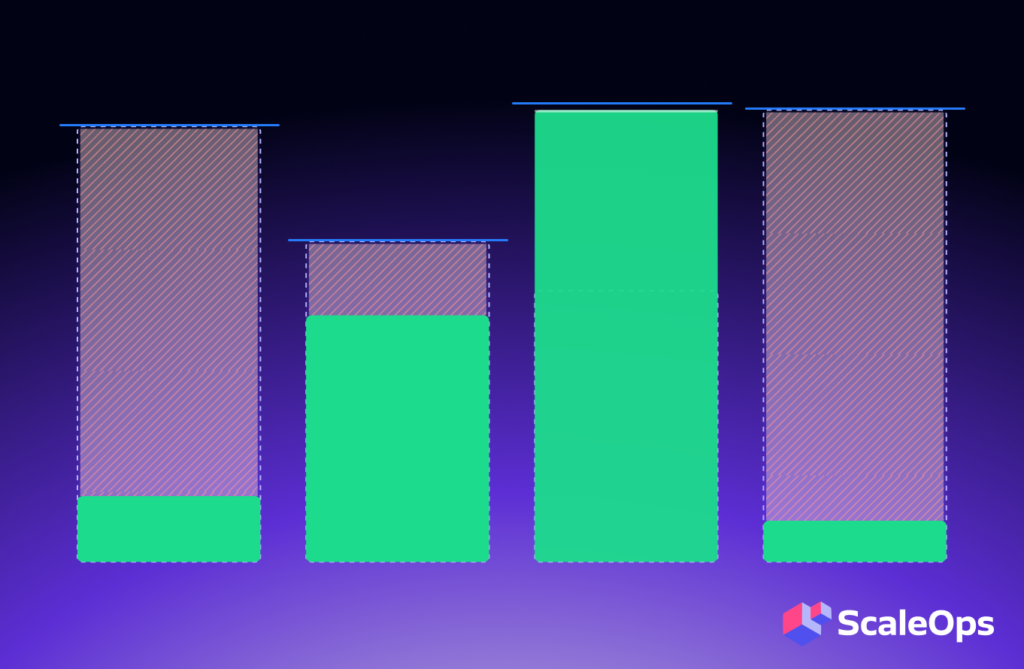
What Is GPU Cost Optimization? GPU cost optimization is the practice of measurin...